用于我司内部分享会,主要结合做过的项目简单介绍一下常用的爬虫模式。
前言
什么是爬虫?
网络蜘蛛
关于爬虫是否合法的讨论?
用爬虫抓取数据,这样的行为是否合法
比较知名的开源的爬虫主要包括:
JAVA : Webmagic,WebCollector,Crawler4j
PYTHON : Scrapy
简单的爬虫
简单的网络爬虫可以只是遍历一个存放URL的集合并通过HttpClient发送网络请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| CloseableHttpClient httpclient = HttpClients.createDefault();
try {
HttpGet httpget = new HttpGet("http://httpbin.org/");
ResponseHandler<String> responseHandler = new ResponseHandler<String>() {
@Override
public String handleResponse( HttpResponse response) throws IOException {
int status = response.getStatusLine().getStatusCode();
if (status >= 200 && status < 300) {
HttpEntity entity = response.getEntity();
return entity != null ? EntityUtils.toString(entity) : null;
}
return null;
}
};
String responseBody = httpclient.execute(httpget, responseHandler);
} catch (IOException e){
e.printStackTrace();
} finally {
try {
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
|
好的爬虫
一个好的爬虫框架相比简单的爬虫,应该包含了以下特性:
- 支持多线程
- 支持代理
- 支持过滤重复URL
- 支持爬取ajax返回信息
- 支持爬取需要登录验证的网页信息(Cookie管理)
- 支持持久化保存爬取到的信息
- 支持错误处理(IP被封禁或者登录信息失效后的处理)
- 支持停止后从断点继续
- 准确,快速地抓取所需信息
为了给一个简单的爬虫整合这些特性,需要做一个简单的框架设计。
优雅的框架设计
Scrapy的框架:
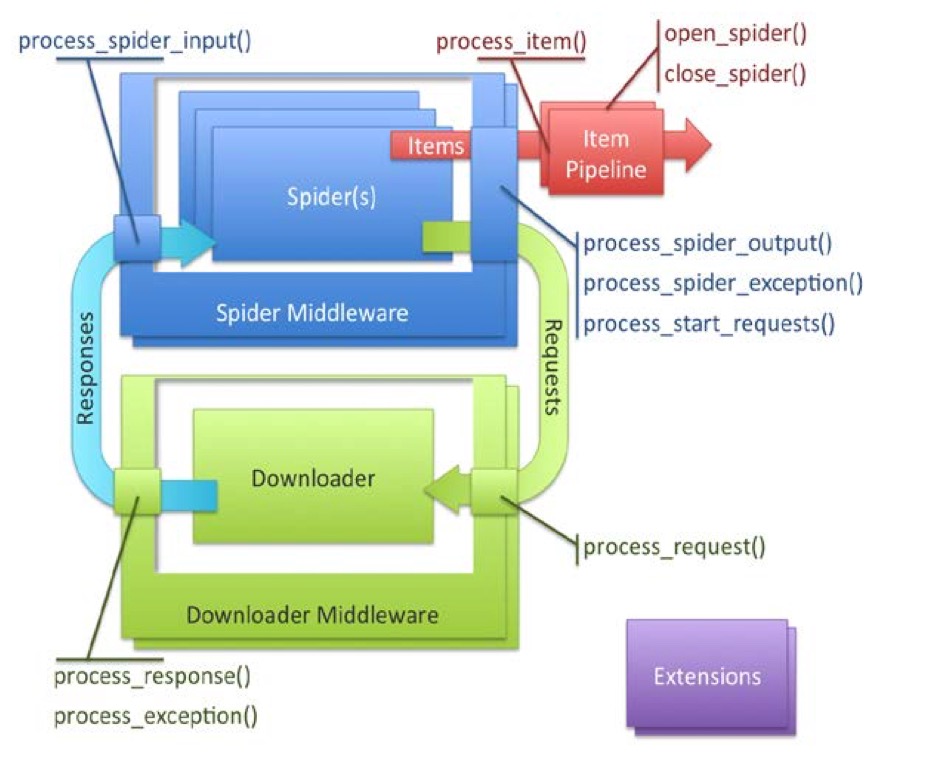
Spider创建Request,处理Response,生成Items和后续Request。Items是从Response中由抽取出的所需信息组合而成的一个个POJO。- Spider生成的
Items经process_item()方法交由一系列的Item Pipelines进行处理。 Pipeline处理Items,可以是保存到数据库,打印到控制台,提交给Elasticsearch等等。Downloader负责实际的下载行为,接收传入的Request请求,输出Response。
Webmagic的框架:
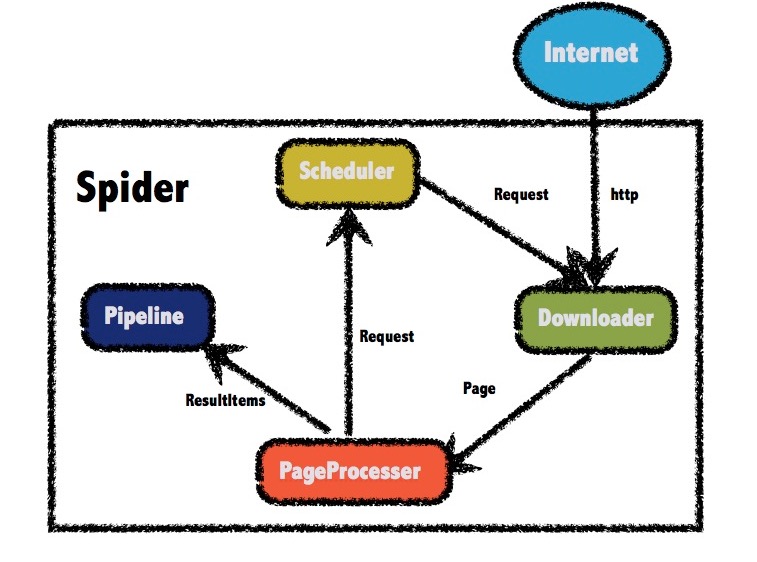
Webmagic的框架设计大部分沿袭了Scrapy:
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。Scheduler负责管理待抓取的URL,以及一些去重的工作。Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。
Webmagic很好的贯彻了面向接口的设计思想,我们可以很容易地对上述的组件进行自定义和扩展。
更进一步,可以通过修改webmgic的源代码来满足我们的定制化需求。
储备知识
通过XPath获取页面元素
常见的从html页面获取元素的方式是通过Jsoup,它支持用CSS Selector方式选择DOM元素,也可过滤HTML文本。
参见renault中Craw168.java的实现
这里主要介绍通过Xpath语法获取页面元素。Xpath语法介绍请见:Xpath语法
由于Jsoup暂不支持Xpath语法,webmagic中集成了Xsoup来实现对Xpath语法的支持。但是由于Xsoup项目疏于维护,对Xpath的语法支持不全,我个人给webmgic添加了JsoupXpath来支持Xpath语法。JsoupXpath项目地址:JsoupXpath
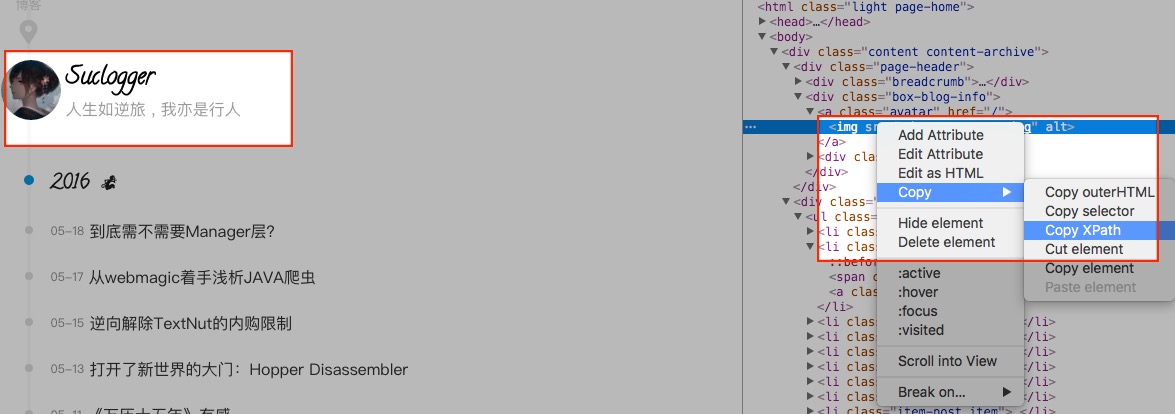
在chrome中调试xpath
通过 开发者工具-元素选择栏 可以快速获取所需元素的xpath路径:
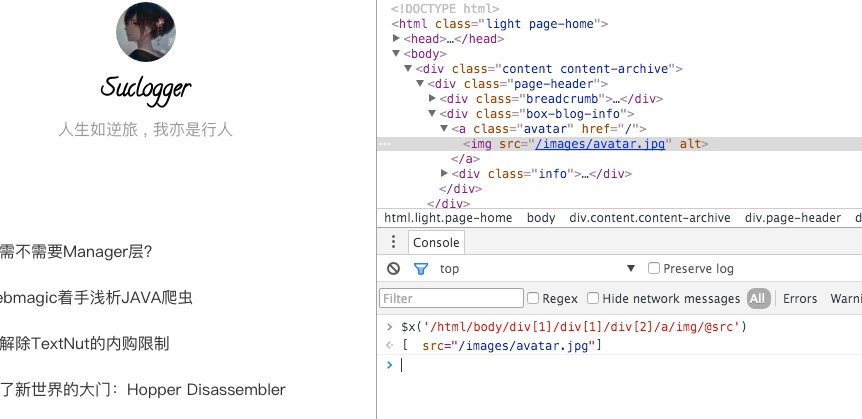
在console中可以使用$x("XPath路径")来定位xpath对应的元素:
在firefox中调试xpath
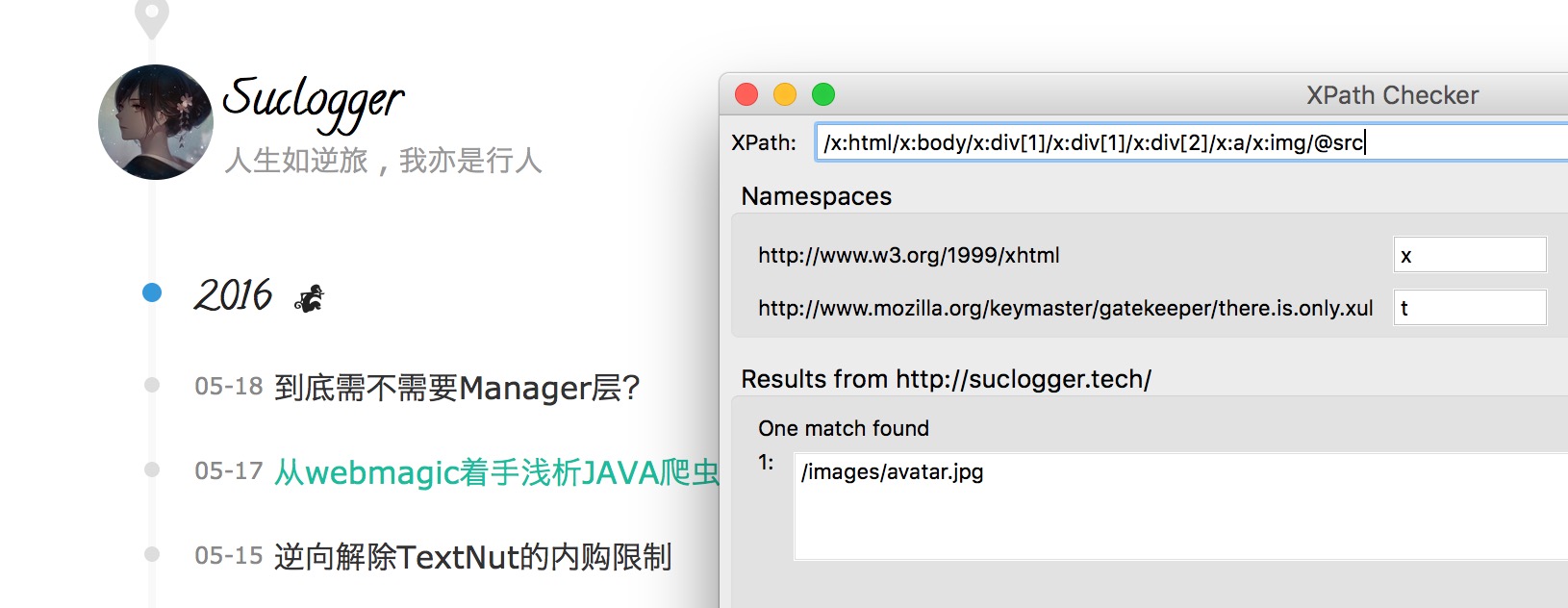
通过安装插件XPath Checker来调试xpath:
查看:
获取元素:
使用xpath需要遵循的几个原则
- 避免使用数组的形式获取元素,如
//*[@id="myid"]/div/div/div[1]/div[2]/div/div[1]/div[1]/a/img。这种形式的xpath表达式是很脆弱的,因为页面的元素的排列很可能受到广告的插入,其他信息的存在与否而导致数组依赖的div的显示与否 等等因素的影响。通过chrome或者firefox自动获取的xpath通常是这种形式,要记得对得到的结果进行一定处理。
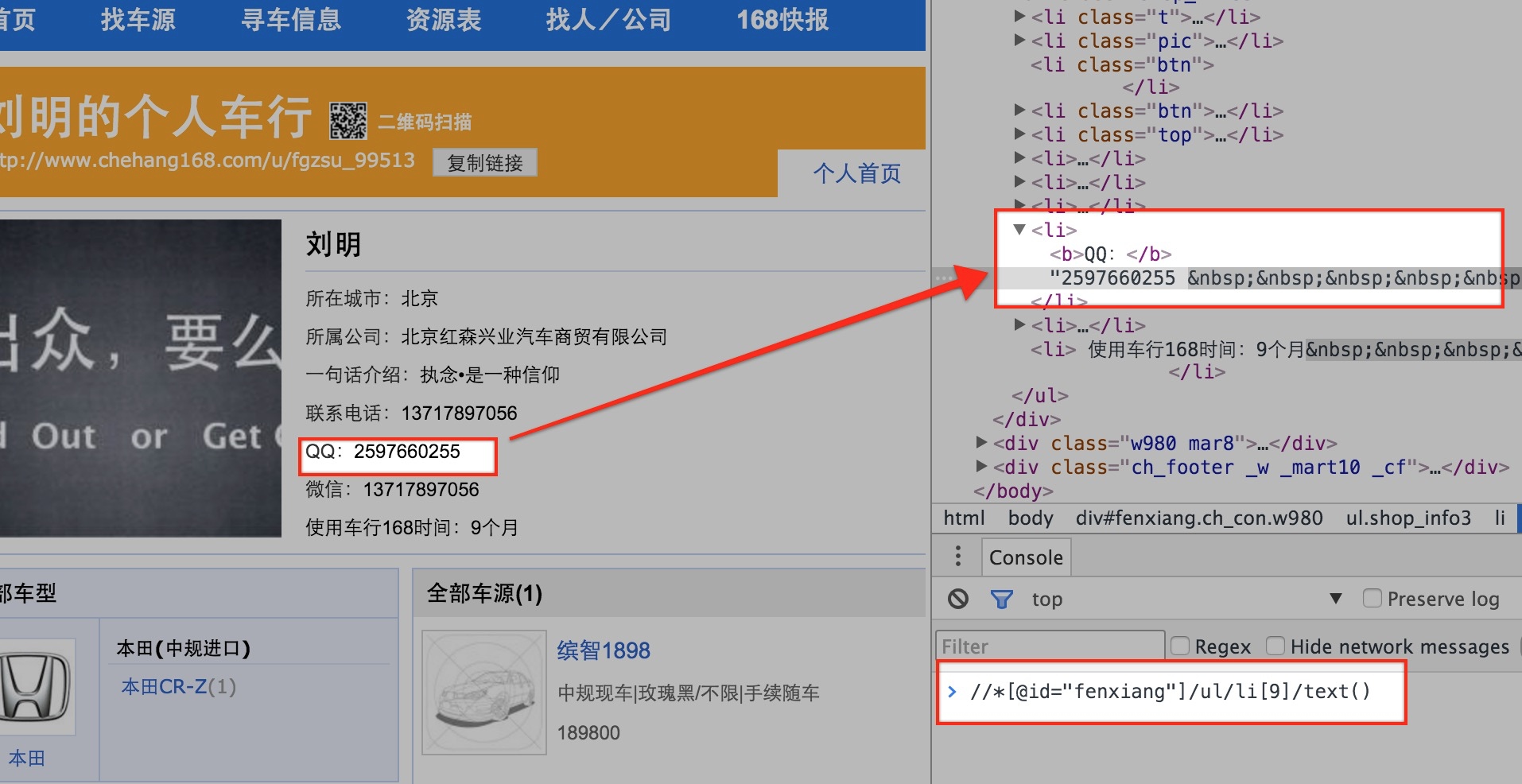
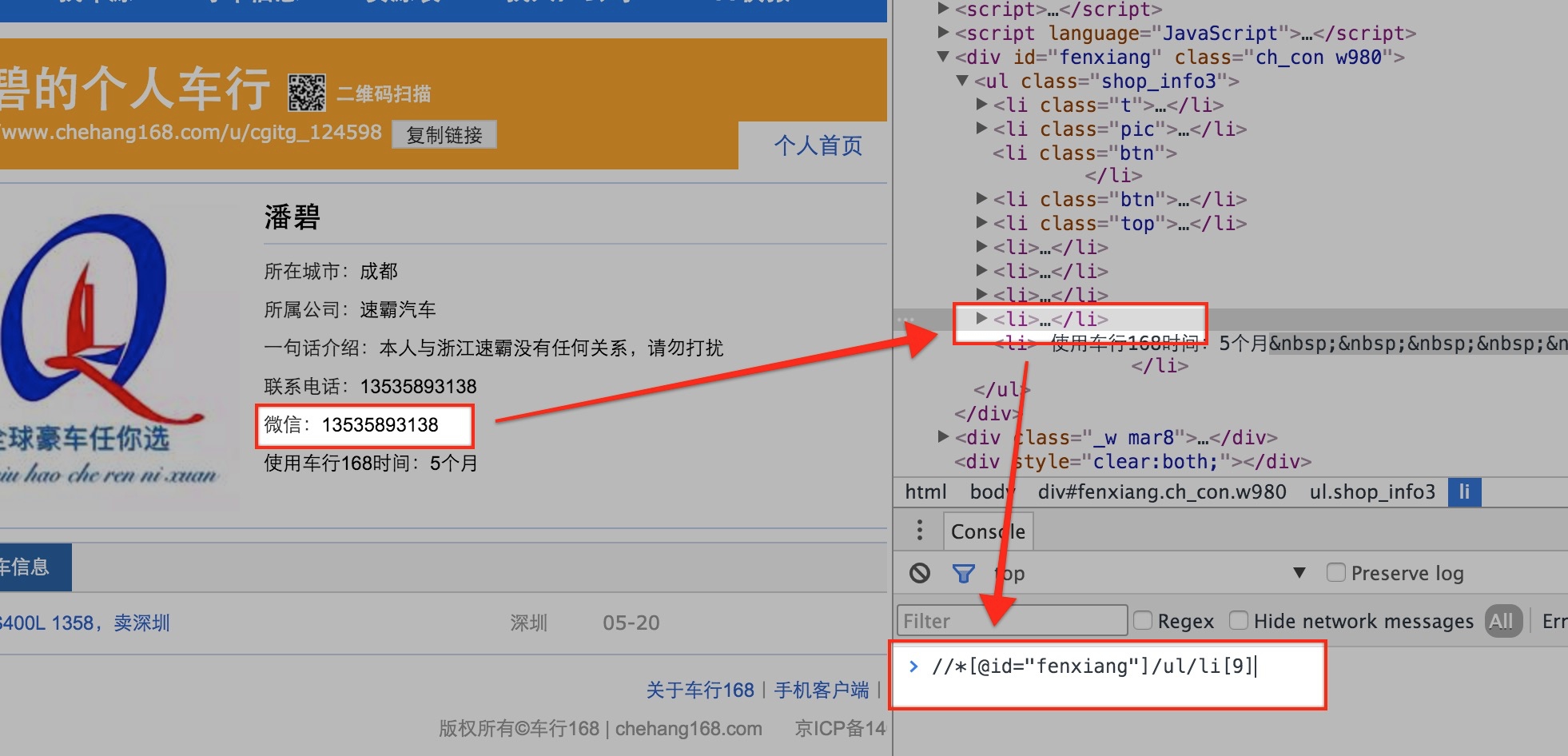
举个例子:
第一个页面上使用li[9]路径来获取页面上的QQ元素,但是第二页面中由于没有对应的元素,导致后面的元素使用了li[9]路径,这时候如果还用li[9]路径来获取页面上的QQ元素,就会得到错误的元素:
  - 避免采用元素的
class属性来获取元素,如//div[@class="red"]/a/img。因为class通常用于控制页面元素的样式,一旦页面的样式风格发生变化,对应元素的class也极有可能发生变化。 - 元素的
id属性通常是最为可靠的,如//*[@id="more_info"]//text()。
接下来就用一个简单的实例进入实战:
一个简单的webmgic的例子
CaoLiuCraw
CaoLiuProcessor.java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public class CaoLiuProcessor implements PageProcessor {
private Site site = Site.me()
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36")
.setCharset("GBK").setDomain("cl.pclmm.org").setSleepTime(5000)
.setHttpProxy(new HttpHost("localhost",6152));
@Override
public void process(Page page) {
String title = page.getHtml().selectDocument(new JsoupXpathSelector("//title/text()"));
List<String> list = page.getHtml().selectDocumentForList(new JsoupXpathSelector("//div[@class='tpc_content do_not_catch']/descendant::input[@type='image']/@src"));
page.putField("title", title);
page.putField("images", list);
Selectable links = page.getHtml().links();
List<String> targeturls = links.regex("http:\\/\\/cl\\.pclmm\\.org\\/htm_data\\/\\d+\\/\\d+\\/\\d+\\.html").all();
List<String> helpurls = links.regex("http:\\/\\/cl\\.pclmm\\.org\\/thread0806\\.php\\?fid=16&search=&page=\\d+").all();
page.addTargetRequests(helpurls);
page.addTargetRequests(targeturls);
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) throws FileNotFoundException, UnsupportedEncodingException {
Spider.create(new CaoLiuProcessor())
// .setScheduler(new FileCacheQueueScheduler("/Users/suclogger/MyWorkspace/caoliua"))
.addUrl("http://cl.pclmm.org/thread0806.php?fid=16&search=&page=1")
.addPipeline(new CaoLiuPip())
.thread(2)
.run();
}
}
|
CaoLiuPip.java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| public class CaoLiuPip implements Pipeline{
private final static String path = "/Users/suclogger/MyWorkspace/caoliu/";
@Override
public void process(ResultItems resultItems, Task task) {
String title = resultItems.get("title");
List<String> list = resultItems.get("images");
if(!StringUtils.isBlank(title) && list.size() > 0) {
StringBuffer imgFileNameNewYuan =new StringBuffer(path)
.append(title) //此处提取文件夹名,即之前采集的标题名
.append("/");
//这里先判断文件夹名是否存在,不存在则建立相应文件夹
Path target = Paths.get(imgFileNameNewYuan.toString());
if(!Files.isReadable(target)){
try {
Files.createDirectory(target);
} catch (IOException e) {
logger.error("folder exist {}", imgFileNameNewYuan.toString(),e);
}
}
for(int i=1;i<list.size();i++){
try {
ThreadPoolFactory.getThreadPool().execute(new DownloadImg(imgFileNameNewYuan.toString(), title,list.get(i)));
} catch (RejectedExecutionException e) {
logger.error("image thread too many, hold on for a minuet");
try {
Thread.sleep(60000);
// retry
ThreadPoolFactory.getThreadPool().execute(new DownloadImg(imgFileNameNewYuan.toString(), title,list.get(i)));
} catch (Exception e1) {
logger.error("shit retry error. do nothing");
}
}
}
}
}
class DownloadImg implements Runnable{
private final HttpHost proxy = new HttpHost("127.0.0.1", 6152, "http");
String imgpath;
String title;
String link;
public DownloadImg(String imgpath, String title, String link) {
this.imgpath = imgpath;
this.title = title;
this.link = link;
}
@Override
public void run() {
try {
String extName=com.google.common.io
.Files.getFileExtension(link);
StringBuffer imgFileNameNew = new StringBuffer(imgpath)
.append((link)
.replaceAll("[\\pP‘’“”]", ""))
.append(".")
.append(extName);
//这里通过httpclient下载之前抓取到的图片网址,并放在对应的文件中
CloseableHttpClient httpclient = HttpClients.createDefault();
RequestConfig config = RequestConfig.custom()
.setProxy(proxy)
.build();
HttpGet httpget = new HttpGet(link);
httpget.setConfig(config);
HttpResponse response = httpclient.execute(httpget);
HttpEntity entity = response.getEntity();
InputStream in = entity.getContent();
File file = new File(imgFileNameNew.toString());
try {
FileOutputStream fout = new FileOutputStream(file);
int l = -1;
byte[] tmp = new byte[1024];
while ((l = in.read(tmp)) != -1) {
fout.write(tmp,0,l);
}
fout.flush();
fout.close();
logger.info("save image : {}", link);
} finally {
in.close();
}
httpclient.close();
} catch (Exception e) {
logger.error("fail saving image : {}",link);
}
}
}
}
|
通过注解编写爬虫的例子
EBookCraw
EBookModel.java(略去了get和set方法):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| @TargetUrl("http:\\/\\/www.allitebooks.com\\/(?!read\\/read.php)*")
@HelpUrl({"http://www.allitebooks.com/\\/page\\/\\d+"})
public class EBookModel {
@ExtractBy(value = "//header[@class='entry-header']/h1[@class='single-title']/text()",notNull = true)
@Formatter(value = "author is %s",formatter = EBookTitleFormatter.class)
private String title;
@ExtractBy(value = "//header[@class='entry-header']/h4/text()",type = ExtractBy.Type.JsoupXpath)
private String brief;
@ExtractBy(value = "//header[@class='entry-header']/div/div[@class*='entry-body-thumbnail']/a/img/@src",type = ExtractBy.Type.JsoupXpath)
private String cover;
@ExtractBy(value = "//div[@class='book-detail']/dl/dd[1]/allText()",type = ExtractBy.Type.JsoupXpath)
private String author;
@ExtractBy(value = "//div[@class='book-detail']/dl/dd[2]/allText()",type = ExtractBy.Type.JsoupXpath)
private String isbn;
@ExtractBy(value = "//div[@class='book-detail']/dl/dd[3]/text()",type = ExtractBy.Type.JsoupXpath)
private String year;
@ExtractBy(value = "//div[@class='book-detail']/dl/dd[4]/text()",type = ExtractBy.Type.JsoupXpath)
private String pages;
@ExtractBy(value = "//div[@class='book-detail']/dl/dd[5]/allText()",type = ExtractBy.Type.JsoupXpath)
private String language;
@ExtractBy(value = "//div[@class='book-detail']/dl//dd[6]/allText()",type = ExtractBy.Type.JsoupXpath)
private String fileSize;
@ExtractBy(value = "//div[@class='book-detail']/dl/dd[7]/allText()",type = ExtractBy.Type.JsoupXpath)
private String fileFormat;
@ExtractBy(value = "//div[@class='book-detail']/dl/dd[8]/allText()",type = ExtractBy.Type.JsoupXpath)
private String category;
@ExtractBy(value = "//div[@class='entry-content']/allText()",type = ExtractBy.Type.JsoupXpath)
private String description;
@ExtractBy("//span[@class='download-links'][1]/a/@href")
private String downloadLink;
@ExtractByUrl("http://www.allitebooks.com/([\\w-]+)")
private String url;
}
|
EBookPip.java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| @Component
public class EBookPip implements PageModelPipeline {
@Autowired
private EBookAO eBookAO;
@Override
public void process(Object o, Task task) {
if(o instanceof EBookModel) {
EBookModel model = (EBookModel) o;
EbookDO edo = new EbookDO();
edo.setTitle(model.getTitle());
edo.setAuthor(model.getAuthor());
edo.setBrief(model.getBrief());
edo.setCategory(model.getCategory());
edo.setCover(model.getCover());
edo.setDescription(model.getDescription());
edo.setDownloadLink(model.getDownloadLink());
edo.setFileFormat(model.getFileFormat());
edo.setFileSize(model.getFileSize());
edo.setIsbn(model.getIsbn());
edo.setLanguage(model.getLanguage());
edo.setYears(model.getYear());
if(!StringUtils.isBlank(model.getPages()) && StringUtils.isNumeric(model.getPages())) {
edo.setPages(Integer.valueOf(model.getPages()));
}
edo.setUrl(model.getUrl());
try {
eBookAO.save(edo);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
|
对一些特性的分析
多线程的支持
多线程的支持是通过一个可监控的TheadPool实现的,用法是通过Spider.thread(N)来开启N个线程。
代理的支持
下文 应对网站的反爬措施 部分中会展开。
过滤重复URL的支持
过滤是通过实现DuplicateRemover接口实现的,默认实现是使用内存中的一个HashSet集来存放已添加进爬取队列的网址。
扩展中还添加了布隆过滤器的实现,适用于巨量网址的去重。
爬取ajax返回信息
通过采集页面链接,并将ajax链接放入爬取队列中可以实现。
支持爬取需要登录验证的网页信息(Cookie管理)
Scrapy替我们托管了所有cookie操作,但是webmagic中没有实现。
通过CookieProvider管理Cookie。
持久信息的支持
如上面的EBookCraw例子,可以在PipeLine中添加数据持久化逻辑。
支持停止后从断点继续
采用FileCacheQueueScheduler来管理爬取链接,爬取中止后可以从文件中读取爬取进度。
应对网站的反爬措施
主要有下面三个方面 :
- 使用webmagic集成的
ProxyPool来管理Proxy - 实现
CookieProvider自定义管理Cookie - 实现
ErrorDetector自定义捕获错误
使用webmagic集成的ProxyPool来管理Proxy
ProxyPool维护了一个代理的有序队列,在每次请求完成后,通过请求的状态码设置当前使用的代理的优先级别返还到队列中,每次请求从队列中根据优先级别重新获取新的代理。
这种方式适用于手上有很多前向代理资源的爬虫,切换起来比较方便,有些情况下可能需要与切换Cookie相互配合使用。
实现CookieProvider自定义管理Cookie
每次请求都会从CookieProvider 中拿一个cookie放入本次请求头中,可以通过方法调用切换cookie。
结合renault演示
增量抓取
通过实现ExistDetector接口,在抓取后续链接的时候调用detect()方法进行判断是否需要抓取该链接。
结合renault演示
爬虫的运行监控
还在雏形阶段
参考:WebMagic Avalon设计草图